Podcast RAG System with Vector Search
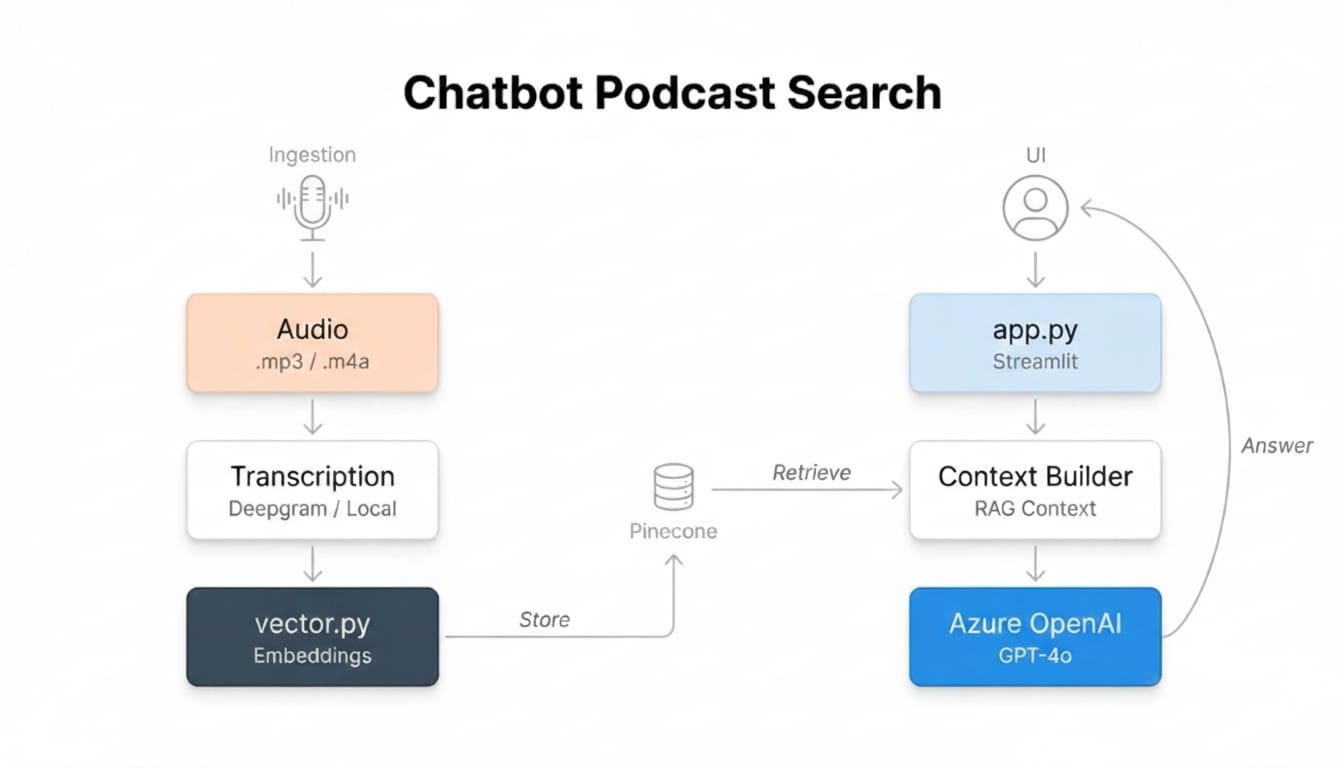
I built a working RAG system that automatically downloaded podcast episodes, transcribed audio using Deepgram, created vector embeddings, and stored them in Pinecone for semantic search. Users could ask questions in natural language and receive contextually relevant answers grounded in actual podcast content.
Implemented the complete RAG pipeline including audio processing, transcript chunking, embedding generation, vector indexing, retrieval logic, and prompt engineering for accurate responses. Built a Streamlit interface that displayed indexed episodes and enabled conversational interaction with the knowledge base.
This project gave me deep understanding of vector database architecture, embedding strategies, semantic search tradeoffs, and cost-performance considerations in RAG systems.


Surabhi skipped presentations and built real AI products.
Surabhi Mehrotra was part of the November 2025 cohort at Curious PM, alongside 20 other talented participants.